
Working Papers
Algorithmic vs. Friend-based Recommendations in Shaping Novel Content Engagement: A Large-scale Field Experiment
with Shan Huang and Leyu Lin (WeChat)
- Currently under Major Revision at Information Systems Research.
- The early version of this work was presented at China India Insights Program (CIIP) 2024, The Twenty-Fifth ACM Conference of Economics and Computation (EC’24), INFORMS Marketing Science Conference 2025, Conference on Information Systems and Technology (CIST) 2025.
Show abstract
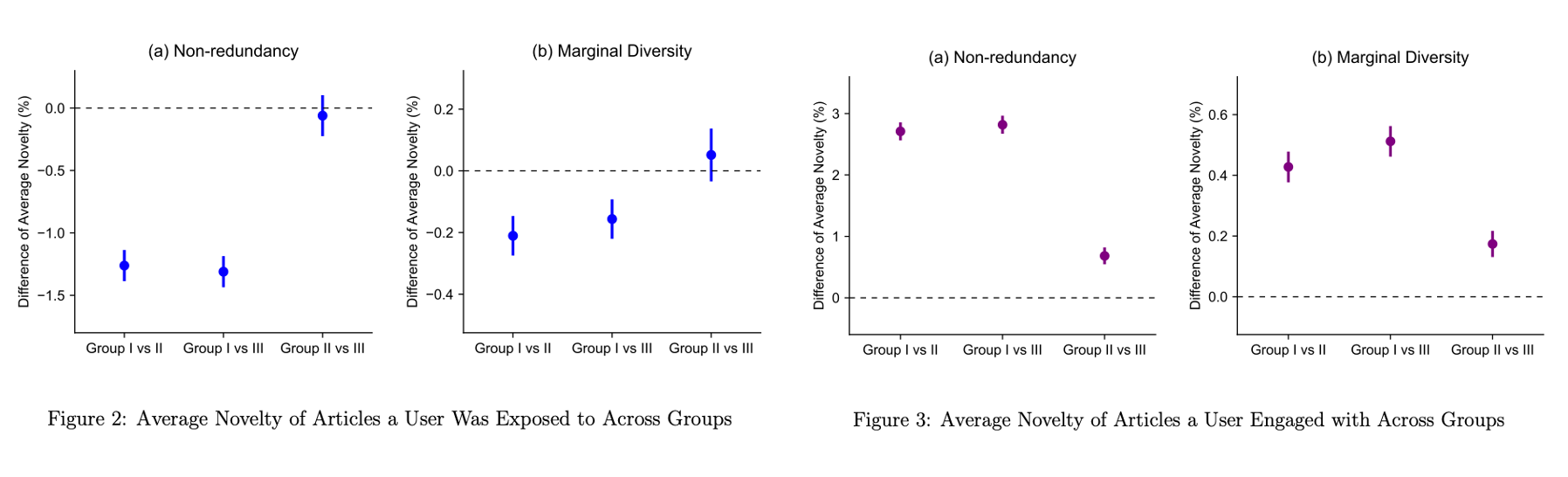
This study identifies the differential impact of algorithmic and friend-based recommendations-the two predominant mechanisms of online content recommendation-on users’ engagement with novel information, characterized as diverse and non-redundant. Our analysis focuses on the influence of different content recommended by algorithms versus friends and the role of social influence, specifically the impact of social cues inherent in friend-based recommendations. We designed and conducted a large-scale field experiment on WeChat, involving 2.1 million users. Participants were randomly assigned to one of three groups: a control group that received content recommended by algorithms, a treatment group that viewed content shared by friends with visible social cues (e.g., friends’ “likes”), and another treatment group that was exposed to friend-shared content with the social cues hidden. The findings reveal a general preference for less novel content across all groups. However, the presence of social cues significantly mitigated this trend, indicating that social influence can encourage engagement with more novel information. Despite algorithms tending to recommend content of lower novelty, users engage more with novel content when recommended by algorithms than by friends with and without social cues. The study also discovered significant variations in engagement with novel content among users of different genders, ages, and city tiers. These results carry important implications for the design of content recommendation systems and inform policymaking regarding the dissemination of information online.
“The Strength of Weak Ties” Varies Across Viral Channels
with Shan Huang and Yuan Yuan
Show abstract
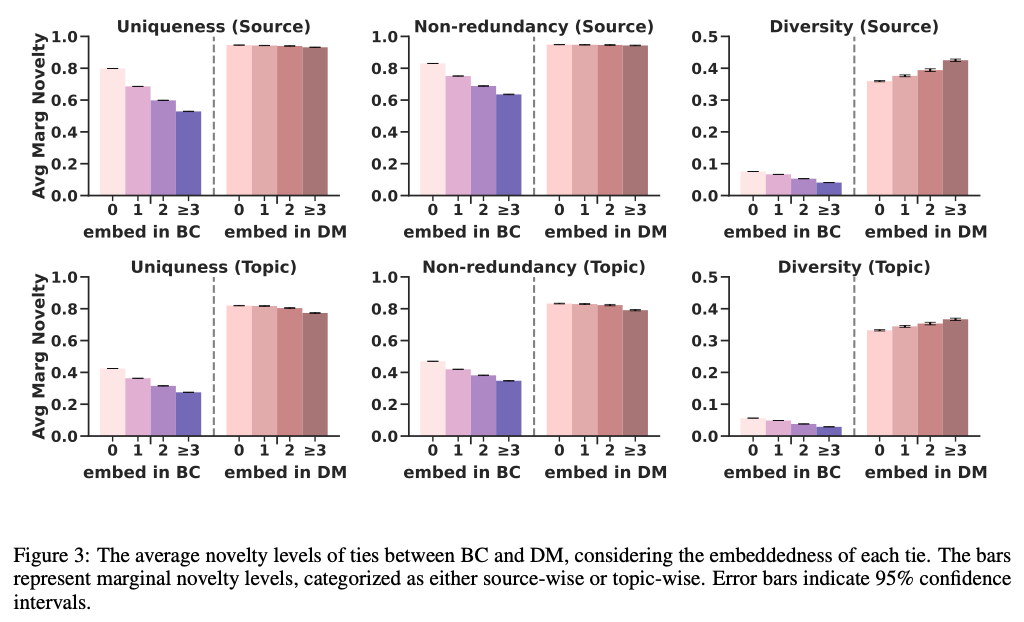
The diffusion of novel information through social networks is essential for dismantling echo chambers and promoting innovation. Our study examines how two major types of viral channels, specifically Direct Messaging (DM) and Broadcasting (BC), impact the well-known “strength of weak ties” in disseminating novel information across social networks. We conducted a large-scale empirical analysis, examining the sharing behavior of 500,000 users over a two-month period on a major social media platform. Our results suggest a greater capacity for DM to transmit novel information compared to BC, although DM typically involves stronger ties. Furthermore, the “strength of weak ties” is only evident in BC, not in DM where weaker ties do not transmit significantly more novel information. Our mechanism analysis indicates that the content selection by both senders and recipients, contingent on tie strength, contributes to the observed differences between these two channels. These findings expand both our understanding of contemporary weak tie theory and our knowledge of how to disseminate novel information in social networks.
Work in Progress
LLMs in Product Selection for Small E-commerce
with Shan Huang
- The early version of this work was presented at INFORMS Annual Meeting 2025, INFORMS Marketing Science Conference 2026.
Show abstract
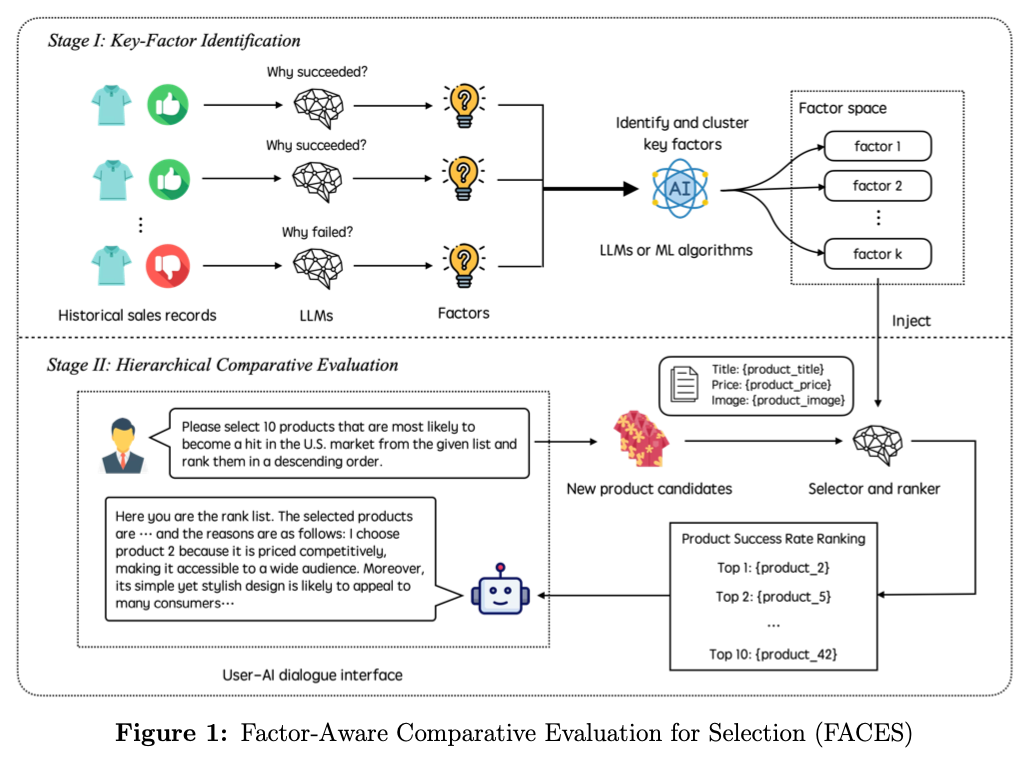
Product selection is critical to the success of small businesses, yet data-driven decision-making is often prohibitively costly in resource-constrained settings. Recent advances in large language models (LLMs) offer a promising alternative for supporting such decisions without requiring extensive data or model training. In this paper, we propose Factor-Aware Comparative Evaluation for Selection (FACES), a training-free, two-stage LLM-based decision framework that emphasizes comparative reasoning rather than pointwise prediction. FACES first induces a compact set of decision factors from historical campaign outcomes and then applies factor-conditioned, hierarchical comparative evaluation within carefully constructed reference groups to rank new candidates. Using real-world data from a representative small e-commerce firm engaged in international trade via Google Ads, we show that LLMs equipped with carefully constructed reference groups and comparative prompts substantially outperform pointwise LLM prompting approaches and competitive machine-learning benchmarks in predicting product-selection outcomes. We further find that larger reference groups can degrade performance, and that alternative information inclusion strategies in reference group construction lead to systematically different decision outcomes. These results provide actionable guidance for small businesses facing cold-start product selection challenges and offer new insights into how LLMs exploit relational structure in decision-making tasks.
An Experience-Buffer Framework for Explainable Satisfaction Prediction with LLMs
with Shan Huang, Tong Wang, and Jinyong Ma (ByteDance)
Show abstract
Satisfaction models typically trade off accuracy for interpretability. We introduce a framework that learns a compact, segment-specific library of satisfaction rules and uses it to steer a large language model at prediction time, without updating any model weights. Customers are first grouped into behavioral segments; within each segment, candidate explanations for satisfaction outcomes are generated and filtered using a prediction-consistency test; the surviving explanations are then distilled into an editable “experience buffer” optimized against held-out performance. In a field partnership with a leading short-video platform, the learned buffer meaningfully improves satisfaction prediction over standard baselines, with gains that replicate across model sizes. Because the rules are human-readable and segment-specific, the resulting predictor also serves as an auditable diagnostic tool for what drives satisfaction in each customer segment.